
Aunalytics President Rich Carlton to Speak at the California and Nevada Credit Union League’s REACH 2021
Carlton’s REACHtalk Will Offer Insights into Leveraging Data with Advanced Analytics to Personalize Customer Intelligence and Achieve Competitive Advantage
Leading Data Platform Provider Will Feature Aunalytics Daybreak for Financial Services in November at Industry Events Attended by California, Nevada, Indiana, and Minnesota Bankers and Credit Unions
South Bend, IN (October 25, 2021) – Aunalytics, a leading data platform company delivering Insights-as-a-Service for enterprise businesses, announced today that the company’s president, Rich Carlton, will be featured as a REACHtalk speaker at the California Nevada Credit Union League’s REACH 2021, November 1-4. Carlton’s talk, Leverage Your Data with Advanced Analytics to Personalize Customer Intelligence and Achieve Competitive Advantage, will take place on November 3, 2021 at 11:45. REACH 2021 will be held at the JW Marriott Desert Springs Resort & Spa. Aunalytics will also feature its advanced data analytics solution for midmarket community banks at three industry events attended by bankers and credit unions from California, Nevada, Indiana, and Minnesota in November.
Aunalytics’ DaybreakTM for Financial Services offers midsize banks and credit unions the ability to gain customer intelligence to grow their lifetime value, predict churn, determine which products to introduce to customers and when, based upon deep learning models that are informed by data. Built from the ground up, Daybreak for Financial Services is a cloud-native data platform that enables users to focus on critical business outcomes. The solution seamlessly integrates and cleanses data for accuracy, ensures data governance, and employs artificial intelligence (AI) and machine learning (ML) driven analytics to glean customer intelligence and timely actionable insights that drive strategic value.
“Midmarket financial institutions can thrive by redefining the local experience and digitally transforming how they operate,” said Carlton. “The ability to target, discover and offer the right services to the right people, at the right time, improves customer relationships, delivers new products and services through data-driven campaigns, and accelerates competitive advantage. We look forward to meeting with bankers and credit unions from California, Nevada, Indiana, and Minnesota and showing how Daybreak for Financial Services can help them strengthen their position in regional markets and compete more effectively.”
Aunalytics will demonstrate Daybreak for Financial Services at:
- California Nevada Credit Union League’s REACH 2021, November 1-4
- Indiana Bankers Association Banking on Women Conference, November 3-4
- Minnesota Credit Union Network ACCELERATE21 Annual Conference, November 18-19
Tweet this: .@Aunalytics President Rich Carlton to Speak at the California Nevada Credit Union League’s REACH 2021 #FinancialServices #Banks #CreditUnions #Dataplatform #DataAnalytics #Dataintegration #Dataaccuracy #AdvancedAnalytics #ArtificialIntelligence #AI #Masterdatamanagement #MDM #DataScientist #MachineLearning #ML #DigitalTransformation #FinancialServices
About Aunalytics
Aunalytics is a data platform company delivering answers for your business. Named a Digital Innovator by analyst firm Intellyx, and selected for the prestigious Inc. 5000 list, Aunalytics provides Insights-as-a-Service to answer enterprise and mid-sized companies’ most important IT and business questions. The Aunalytics® cloud-native data platform is built for universal data access, advanced analytics and AI while unifying disparate data silos into a single golden record of accurate, actionable business information. Its DaybreakTM industry intelligent data mart combined with the power of the Aunalytics data platform provides industry-specific data models with built-in queries and AI to ensure access to timely, accurate data and answers to critical business and IT questions. Through its side-by-side digital transformation model, Aunalytics provides on-demand scalable access to technology, data science, and AI experts to seamlessly transform customers’ businesses. To learn more contact us at +1 855-799-DATA or visit Aunalytics at http://www.aunalytics.com or on Twitter and LinkedIn.
PR Contact:
Denise Nelson
The Ventana Group for Aunalytics
(925) 858-5198
dnelson@theventanagroup.com
Aunalytics Wins a 2021 Digital Innovator Award from Intellyx
South Bend, IN (October 19, 2021) - Aunalytics, a leading data platform company delivering Insights-as-a-Service for enterprise businesses, announced today that it has received a 2021 Digital Innovator Award from Intellyx, an analyst firm dedicated to digital transformation.
As an industry analyst firm that focuses on enterprise digital transformation and the disruptive technology providers that drive it, Intellyx interacts with numerous innovators in the enterprise IT marketplace. Intellyx established the Digital Innovator Awards to honor technology providers that are chosen through the firm’s rigorous briefing selection process and deliver a successful briefing.
“At Intellyx, we get dozens of PR pitches each day from a wide range of vendors,” said Jason Bloomberg, President of Intellyx. “We will only set up briefings with the most disruptive and innovative firms in their space. That’s why it made sense for us to call out the companies that made the cut.”
Aunalytics offers a robust, cloud-native data platform built to enable universal data access, powerful analytics, and AI-driven answers. Customers can turn data into answers with the secure, reliable, and scalable data platform deployed and managed by technology and data experts as a service. The platform represents Aunalytics’ unique ability to unify all the elements necessary to process data and deliver AI end-to-end, from cloud infrastructure to data acquisition, organization, and machine learning models – all managed and run by Aunalytics as a secure managed service. And, while typically large enterprises are in a better position to afford advanced database and analytics technology, Aunalytics pairs its platform with access to its team’s expertise to help mid-market companies compete with enterprise companies.
“We’re honored to have been selected by a respected analyst firm such as Intellyx to receive its 2021 Digital Innovation Awards,” said Rich Carlton, President of Aunalytics. “It is a testament to the value we bring to our customers who are challenged with the need to achieve critical insights to operate more efficiently and gain a competitive edge.”
For more details on the award and to see other winning vendors in this group, visit the 2021 Intellyx Digital Innovator awards page here.
Tweet this: .@Aunalytics Aunalytics Wins a 2021 Digital Innovator Award from Intellyx #Dataplatform #Dataanalytics #Dataintegration #Dataaccuracy #Advancedanalytics #Cloudnative #Artificialintelligence #AI #Masterdatamanagement #MDM #Datascientist #Machinelearning #ML #Digitaltransformation
About Aunalytics
Aunalytics is a data platform company delivering answers for your business. Named a Digital Innovator by analyst firm Intellyx, and selected for the prestigious Inc. 5000 list, Aunalytics provides Insights-as-a-Service to answer enterprise and midsize companies’ most important IT and business questions. The Aunalytics® cloud-native data platform is built for universal data access, advanced analytics and AI while unifying disparate data silos into a single golden record of accurate, actionable business information. Its DaybreakTM industry intelligent data mart combined with the power of the Aunalytics data platform provides industry-specific data models with built-in queries and AI to ensure access to timely, accurate data and answers to critical business and IT questions. Through its side-by-side digital transformation model, Aunalytics provides on-demand scalable access to technology, data science, and AI experts to seamlessly transform customers’ businesses. To learn more contact us at +1 855-799-DATA or visit Aunalytics at https://www.aunalytics.com or on Twitter and LinkedIn.
PR Contact:
Denise Nelson
The Ventana Group for Aunalytics
(925) 858-5198
dnelson@theventanagroup.com

Aunalytics Gains Significant Momentum in Q2 2021 with 40% Increase in Quarter over Quarter Growth of Analytic Data Platform Deployments
Award Winning Data Platform Provider Achieves Key Milestones and Expands Reach as it Delivers Universal Data Access and Advanced Analytics to Drive Digital Transformation for Customers
South Bend, IN (September 22, 2021) - Aunalytics, a leading data platform company delivering Insights-as-a-Service for enterprise businesses, continued to demonstrate exceptional growth and momentum during the second quarter of 2021. Deployment of the Aunalytics Daybreak™ analytic database providing customer intelligence for the financial services industry increased 40%. Further, late in the quarter, the company launched a new tiered data model that reduces implementation time by 50% to place actionable revenue growth insights in the hands of its financial services clients faster. It is anticipated that implementations will continue to accelerate with this advancement. The company also announces a 25% increase in new clients in its enterprise cloud and managed services business lines.
The global big data and analytics market is expected to grow at a CAGR of 10% in the forecast period of 2021-2026, reaching $450 billion by 2026. Organizations have started to capitalize on big data by generating and leveraging key insights, strategies, and business decisions to provide better customer experiences, improve efficiency, and remain competitive by gaining answers to critical questions in nearly every functional aspect of their business.
Aunalytics offers a robust, cloud-native data platform built to enable universal data access, powerful analytics, and AI-driven answers. Customers can turn data into answers with the secure, reliable, and scalable data platform deployed and managed by technology and data experts as a service. The platform represents Aunalytics’ unique ability to unify all the elements necessary to process data and deliver AI end-to-end, from cloud infrastructure to data acquisition, organization, and machine learning models – all managed and run by Aunalytics as a secure managed service. And, while typically large enterprises are in a better position to afford advanced database and analytics technology, Aunalytics pairs its platform with access to its team’s expertise to help mid-market companies compete with enterprise players.
Significant milestones Aunalytics achieved in Q2 of this year include:
- Daybreak analytic database deployment 40% growth
- 25% new customer growth in cloud and managed services business lines
- The company announced that its Aunalytics® Cloud solution has achieved Federal Risk and Authorization Management Program (FedRAMP) Ready status and is actively working toward FedRAMP certification.
- The introduction of a new tiered data model workflow added to Daybreak 3.0 for faster implementation resulting in customers receiving answers faster. Implementation time has been reduced by 50%.
- The introduction of new Churn Propensity Smart Feature™ added to Daybreak 3.0: a predictive model that analyzes customer transactional data for indicators that a customer is likely to churn so that financial institutions can take action before losing customers.
- The introduction of new Product Propensity Smart Feature added to Daybreak 3.0: a machine learning powered customized dataset for each customer’s propensity for new financial services products by type modeled on customer behaviors prior to opening new accounts to better cultivate long-term customer relationships with intelligent marketing.
- The introduction of new Risk Scoring for Loan Default at Time of Application Smart Feature added to Daybreak 3.0: a machine learning powered data model to reduce lending risk based upon an institution’s historical loan defaults that identifies risk of a particular loan application at the time of underwriting.
- Aunalytics Accelerates Insights-as-a-Service Offering Through Ohio Expansion - The integration of Ohio-based managed services provider NetGain and Aunalytics in February 2021 has allowed the company to expand its footprint in the state and extended its solution portfolio, including Aunsight™ Golden Record and the Daybreak Analytic Database, to new customers in the region.
- Introduction of the Alliance Partner Program to Accelerate Adoption of its Cloud Native Data Analytics Platform and Capitalize on the Multi-Billion Dollar Market Opportunity. The Alliance Partner Program was developed to give ISVs and technology partners the dedicated resources and support to ensure success and drive new recurring revenue opportunities and long-term value for clients.
- New partnerships
- Aunalytics and AC3 Announce a Strategic Partnership that Empowers Oncology Practice Groups to Modernize Their Businesses Through Advanced Analytics and Valuable Business Insights
- Aunalytics and Stonebridge Consulting Announce Strategic Partnership to Deliver Data Accuracy and Advanced Data Management Solutions for the Oil and Gas Industry.
Kelly Jones, former president and chief operations officer of NetGain Information Systems (acquired by Aunalytics in February 2021) and now vice president of Integration Services at Aunalytics, was recognized as one of CRN’s 2021 Women of the Channel as well as one of CRN’s Power 60 Solution Providers.
- Aunalytics was named one of CRN’s Coolest Business Analytics Companies of the 2021 Big Data 100, a list of vendors that CRN says “solution providers should know in the big data business.”
“We’re extremely pleased with our continued momentum and the milestones achieved in the second quarter of this year,” said Rich Carlton, President and CRO of Aunalytics. “It demonstrates how businesses are eager to leverage their data for competitive gain, and yet midsize companies are often out-teched by larger rivals with bigger budgets for advanced data analytics tools and talent. We remain committed to providing the ability to quickly and accurately answer our customers’ important IT and business questions to help drive growth and improve the bottom line as we continue to expand our position as a leading data platform provider.”
Tweet this: .@Aunalytics Gains Significant Momentum in Q2 2021 with 40% Increase in Quarter over Quarter Growth of Analytic Data Platform Deployments #Dataplatform #Dataanalytics #Dataintegration #Dataaccuracy #ArtificialIntelligence #AI #Masterdatamanagement #MDM #DataScientist #MachineLearning #ML #DigitalTransformation #FinancialServices
About Aunalytics
Aunalytics is a data platform company delivering answers for your business. Aunalytics provides Insights-as-a-Service to answer enterprise and mid-sized companies’ most important IT and business questions. The Aunalytics® cloud-native data platform is built for universal data access, advanced analytics and AI while unifying disparate data silos into a single golden record of accurate, actionable business information. Its Daybreak™ industry intelligent data mart combined with the power of the Aunalytics data platform provides industry-specific data models with built-in queries and AI to ensure access to timely, accurate data and answers to critical business and IT questions. Through its side-by-side digital transformation model, Aunalytics provides on-demand scalable access to technology, data science, and AI experts to seamlessly transform customers’ businesses. To learn more contact us at +1 855-799-DATA or visit Aunalytics at https://www.aunalytics.com or on Twitter and LinkedIn.
PR Contact:
Denise Nelson
The Ventana Group for Aunalytics
(925) 858-5198
dnelson@theventanagroup.com
Aunalytics on ActualTech Media's Spotlight Series
Aunalytics on ActualTech Media's Spotlight Series
Aunalytics CMO Katie Horvath sat down with David Davis of ActualTech Media to discuss helping companies with their data challenges. By providing Insights as a Service, we make sure data is managed and organized so it’s ready to answer your business questions.


2021 Missouri Bankers Association Annual Convention
Missouri Bankers Association Annual Convention & Trade Show
Chateau on the Lake Resort Spa & Convention Center, Branson, MO
Aunalytics is attending the 2021 MBA Annual Convention as a Gold Sponsor
Aunalytics, a leading data platform company delivering Insights-as-a-Service for enterprise businesses, will join the upcoming Missouri Bankers Association Annual Convention as a Gold Sponsor, July 13-16 in Branson, MO. Aunalytics will feature its Daybreak™ for Financial Services solution with advanced analytics that enable bankers to more effectively identify and deliver new services and solutions for their customers for greater competitive advantage.
What are Smart Features?
Machine learning is a leading component of today’s business landscape, but even many forward-looking business leaders in the mid-market have difficulty developing a strategy to leverage these cutting edge techniques for their business. At Aunalytics, our mission is to improve the lives and businesses of others through technology, and we believe that what many organizations need to succeed in today’s climate is access to machine learning technology to enhance the ability to make data driven-decisions from complex data sources.
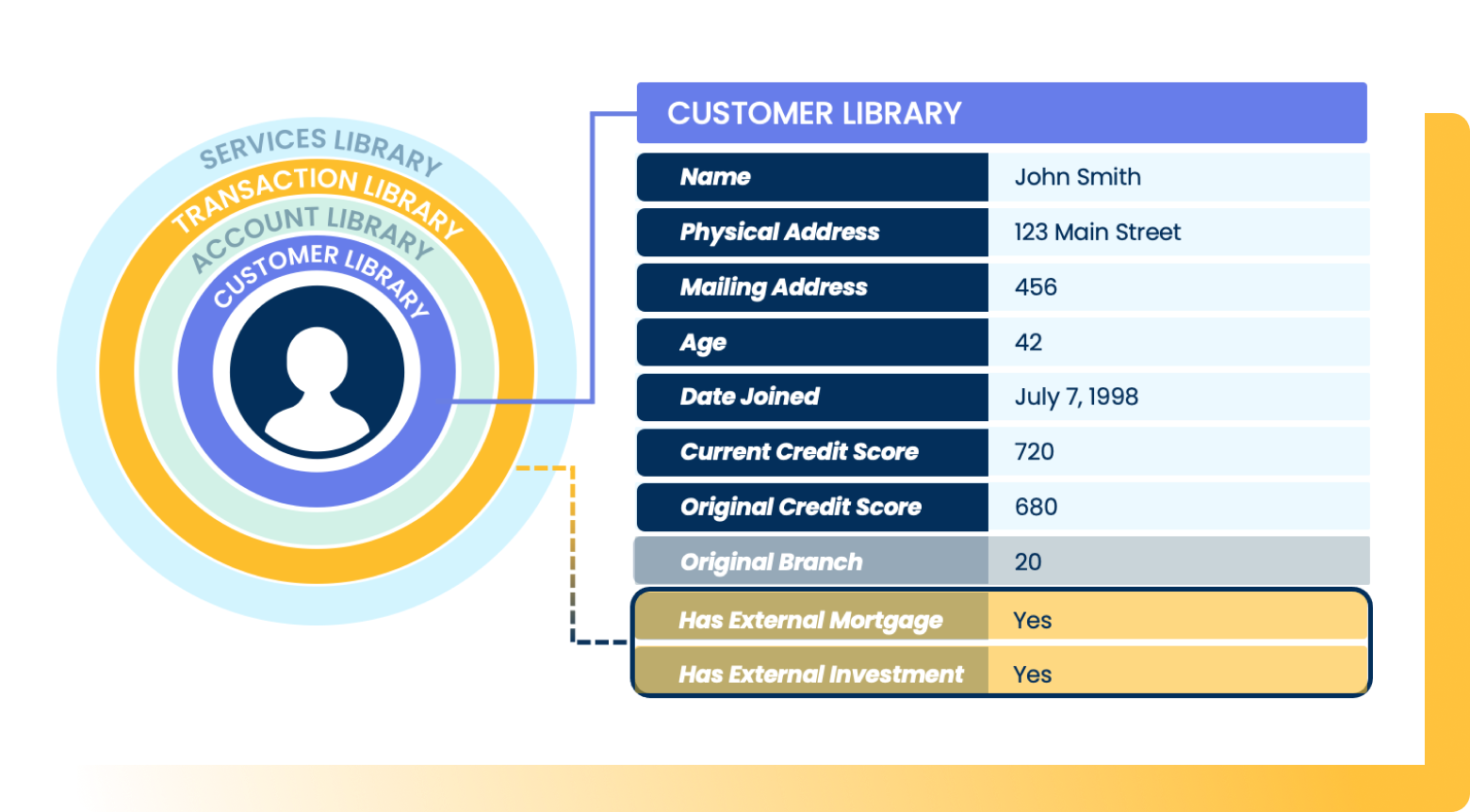
Imagine having the ability to look at a particular customer and understand based on past data how that individual compares in terms of various factors driving that business relationship:
- Which of our products is this customer most likely to choose next?
- How likely is this customer to default or become past due on an invoice?
- What is churn likelihood for this customer?
- What is the probable lifetime value of this customer relationship?
Aunalytics’ Innovation Lab data scientists have combed through data from our clients in industries like financial services, healthcare, retail, and manufacturing and have developed proprietary machine learning techniques based on a solid understanding of the data commonly collected by businesses in these sectors.
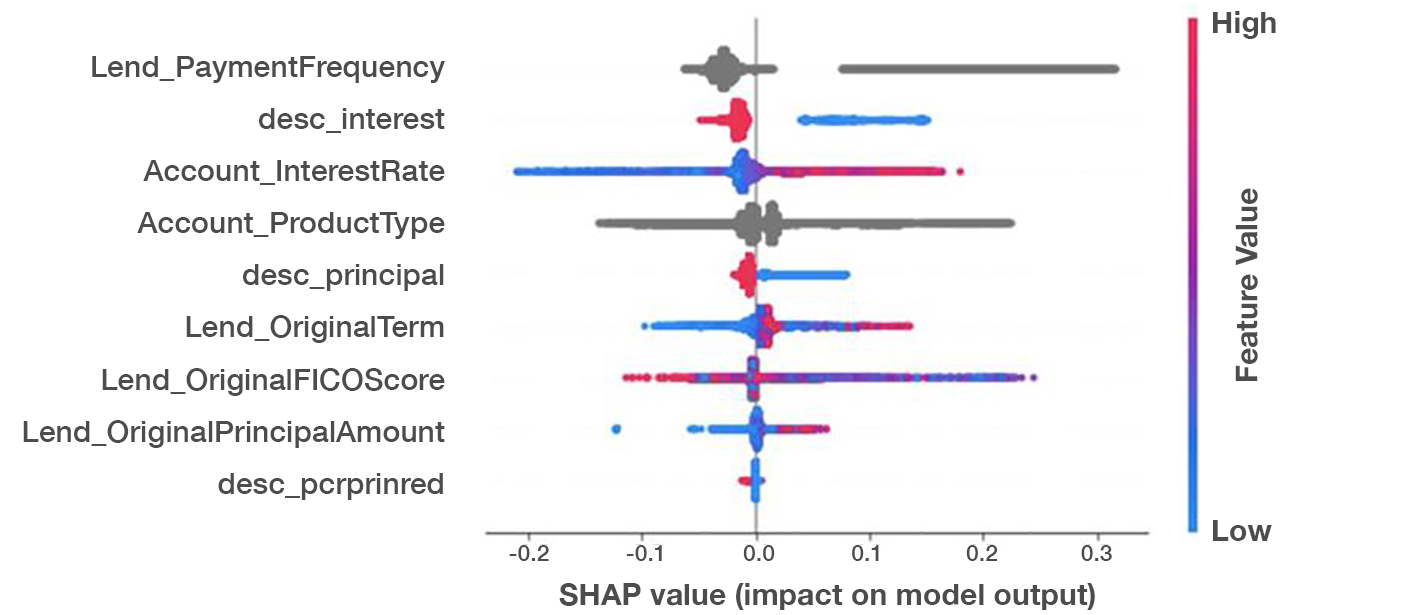
A SHAP (Shapley Additive Explanations) value chart for a remarkably accurate loan default risk model we developed shows which features have the highest impact on risk prediction.
From this, we append insights gleaned from machine learning to data models. We add high value fields to customer records to reveal insights about a customer learned from our algorithms. Smart Features provide answers to pressing business questions to recommend next steps to take with a particular customer to deepen relationships, provide targeted land and expand sales strategies, provide targeted marketing campaigns for better customer experiences, and yield business outcomes.
Machine learning techniques enable more accurate models of risk, propensity, and customer churn because they represent a more complex model of the various factors that go into risk modeling. Our models deliver greater accuracy than simpler, statistical models because they understand the relationship between multiple indicators.
Smart Features are one way that Aunalytics provides value to our clients by lending our extensive data science expertise to client-specific questions. Through these machine learning enriched data points, clients can easily understand a particular customer or product by comparing it to other customers with similar data. Whether you want to know if a customer is likely to select a new product, their default risk, churn likelihood, or any other number of questions, our data scientists and business analysts are experienced and committed to answering these questions based on years of experience with businesses in your industry.
Where Can I Find an End-to-End Data Analytics Solution?
The data analytics landscape has exploded over the past decade with an ever-growing selection of products and services: literally thousands of tools exist to help business deploy and manage data lakes, ETL and ELT, machine learning, and business intelligence. With so many tools to piece together, how do business leaders find the best one or ones? How do you piece them together and use them to get business outcomes? The truth is that many tools are built for data scientists, data engineers and other users with technical expertise. With most tools, if you do not have a data science department, your company is at risk for buying technologies that your team does not have the expertise to use and maintain. This turns digital transformation into a cost center instead of sparking data driven revenue growth.

Image credit: Firstmark
https://venturebeat.com/2020/10/21/the-2020-data-and-ai-landscape/

Aunalytics’ side-by-side service model provides value that goes beyond most other tools and platforms on the market by providing a data platform with built-in data management and analytics, as well as access to human intelligence in data engineering, machine learning, and business analytics. While many companies offer one or two similar products, and many consulting firms can provide guidance in choosing and implementing tools, Aunalytics integrates all the tools and expertise in one end-to-end solution built for non-technical business users. The success of a digital transformation project should not be hitting implementation milestones. The success of a digital transformation project should be measured in business outcomes.

Aunalytics’ Client Success Team Drives Measurable Business Value
Transitioning to a more data-driven organization can be a long, complicated journey. A complete digital transformation is more than simply adopting new technologies (though that is an important component.) It requires change at all levels of the business in order to pivot to a more data-enabled, customer-focused mindset. Aunalytics Client Success is committed to helping organizations digitally transform by guiding and assisting them along every step of the journey, and ultimately, allowing them to thrive.
Below, the Client Success (CS) team has answered some of the most common questions about what they do and how they help organizations achieve measurable business outcomes.
What is Client Success?
Aunalytics CS partners with clients to become their trusted advisor, by building a customized CS Partnership Plan utilizing the client’s unique business needs as the core goals. The CS Partnership Plan creates an exceptional client experience by consistently applying a combination of our team and technology to deliver measurable value and business outcomes for our clients.
What are the main goals of the Aunalytics Client Success team?
The Client Success team has four main goals:
- Designing targeted client experiences (by industry, product, and digital transformation stage)
- Recommending targeted next steps by simplifying and synthesizing complex information
- Delivering proactive and strategic support from onboarding to solution launch, ongoing support, and consulting
- Collecting and responding to client feedback on ways our service delivery can evolve
What are the various roles within the CS team?
There are two main roles within the CS team that interact with clients on a regular basis. The first is the Client Success Manager (CSM). The CSM manages day-to-day client tactical needs, providing updates and direction throughout the onboarding process. As the liaison between clients and the Aunalytics team, the CSM synthesizes complex information into clear actions, mitigates any roadblocks that may occur, and clearly communicates project milestones. The CSM works closely with the clients throughout their partnership with Aunalytics, from onboarding, adoption, support, and engagement.
The Client Success Advisor (CSA) works on high-level strategy with each client, translating Aunalytics’ technology solutions into measurable business outcomes. They partner with the clients’ key stakeholders to understand their strategic objectives and create a custom technology roadmap that identifies the specific steps necessary to reach their digital transformation goals. These goals are integrated into the client’s specific CS Partnership Plan to ensure we are aligned on objectives and key results, with clear owners, timelines, and expected outcomes.
How often can a client expect to hear from a CS team member throughout their engagement with Aunalytics?
The CS team is introduced to clients at the initial kickoff meeting and CSMs initiate weekly touch points to ensure onboarding milestones are being met and to communicate action items, responsible parties, and next steps. During these calls the CS team (CS Manager, CS Advisor, Data Engineer, & Business Analyst) will review the project tracker—highlighting recent accomplishments, key priorities, and next steps. Each item is documented, assigned an owner, a timeline, and clear expectations around completion criteria.
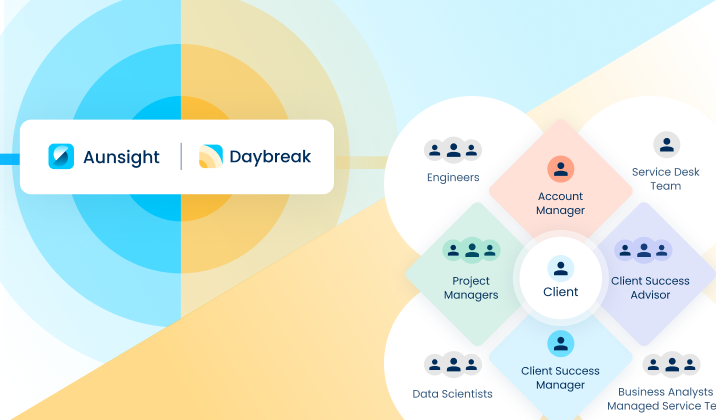
What is the Aunalytics “Side-by-Side Support” model and how does the CS team help facilitate this?
Our side-by-side service delivery model provides a dedicated account team, comprised of technology (Data Engineers (DE), Data Scientists (DS), and Business Analysts) and data experts (Product Managers, Data Ingestion Engineers, and Cloud Infrastructure Team), to help transform the way our clients work. The account team collaborates across the company, in service of the client, to ensure that everyone on the team is driving towards the client’s desired outcomes. The CSA captures this information in the CS Partnership Plan to ensure alignment, key priorities, and ownership of time-bound tasks.
The CS team partners with Aunalytics’ Product, Ingestion, and Cloud teams to share client questions, recommendations, and future enhancement ideas. The Partnership Plan is a custom document that evolves with the client’s ever-changing needs. The CSA reviews the Partnership Plan with the client every quarter to capture new goals, document accomplishments, and create feasible timelines for implementation. The goal of the CSA is to create a relationship with the client, in which they view the CSA as a key member of their internal team (e.g. the same side of the table vs. a vendor).
A successful partnership with Aunalytics’ Client Success team is when concrete business outcomes and value are realized by the client, through the use of Aunalytics’ solutions (products + service).
What are some examples of business outcomes that CS has helped Daybreak for Financial Services clients achieve?
In addition to guidance throughout the initial implementation of Daybreak, CS has assisted banks and credit unions with the execution of a number of actionable business cases, such as:
- Assisting Financial Institutions with implementation of self-service analytics programs;
- Improving collection and recovery rates on loans;
- Implementing pattern recognition to make sure that risk and collection departments are efficiently targeting the most at-risk loans;
- Creating data driven marketing programs to offer personalized services, next-best products, and onboarding. Data-driven marketing allows financial institutions to be more efficient with their marketing dollars and track campaign outcomes better;
- Integration with 3rdparty software systems.
The Aunalytics Client Success team is instrumental in helping clients realize measurable business value. Together with Aunalytics’ strong technology stack, this side-by-side delivery model ensures that all clients are equipped with the resources they need to affect positive change within the organization and achieve their digital transformation goals.
