
Digital Banking & Analytics Initiatives Top Banking Technology Predictions for 2022
 When looking at major trends and predictions regarding banking technology for mid-market financial institutions this year, two themes top the list—digital banking and analytics initiatives. Mid-market financial institutions have been placing more emphasis on digital banking and analytics initiatives in recent years as consumer preferences and technologies evolve. But over the past two years, the pace of this shift has accelerated. As we move away from the initial shock to our economy caused by the global pandemic, and continue to feel its ripple effects in the supply chain, the jobs market, and price increases in nearly every sector, 2022 reveals that time is of the essence for new leaders to emerge in mid-market banking with smart technology investments.
When looking at major trends and predictions regarding banking technology for mid-market financial institutions this year, two themes top the list—digital banking and analytics initiatives. Mid-market financial institutions have been placing more emphasis on digital banking and analytics initiatives in recent years as consumer preferences and technologies evolve. But over the past two years, the pace of this shift has accelerated. As we move away from the initial shock to our economy caused by the global pandemic, and continue to feel its ripple effects in the supply chain, the jobs market, and price increases in nearly every sector, 2022 reveals that time is of the essence for new leaders to emerge in mid-market banking with smart technology investments.
Unfortunately, simply providing a mobile banking app is not enough in a world where customers demand personalized digital interactions. A banking institution must augment digital banking technology with customer intelligence and implement data-driven decision making through AI-enabled analytics. This is not a minor undertaking. It may require the bank to make a fundamental shift in the way it operates and the initiatives it prioritizes. Cultivating a data-driven culture is essential in meeting this goal. However, this can be challenging. Many mid-market financial institutions may not yet have the technology and talent needed to facilitate a data-driven culture. It requires data management and advanced analytics technology and expertise. Organizations need to take steps now in order to not only stay relevant—but to truly thrive—in this ever-evolving industry. Staying up-to-date on the latest technological trends is the first step in the process.
To learn more about the top technology trends in mid-market banking, and steps community banks and credit unions can take now in order to bridge the competitive gap, download our eBook, Top 5 Imperative 2022 Banking Technology Predictions for Mid-Market Financial Institutions.

Data Analytics Helps Midsize Financial Institutions Thrive
 The financial services industry continues to rapidly evolve. Between mergers, changing customer demographics, and increasing reliance on digital platforms for banking interactions, it can be difficult for smaller institutions to compete with large, national, and online-only banks in this crowded market. As customer interactions become increasingly digital, community and mid-market banks and credit unions are challenged with maintaining the competitive advantage that local, personalized, white-glove service has traditionally afforded them. This is why customer intelligence powered by data analytics helps midsize banks and credit unions thrive. However, they oftentimes struggle to achieve the valuable business insights that untapped data could provide to improve their operations.
The financial services industry continues to rapidly evolve. Between mergers, changing customer demographics, and increasing reliance on digital platforms for banking interactions, it can be difficult for smaller institutions to compete with large, national, and online-only banks in this crowded market. As customer interactions become increasingly digital, community and mid-market banks and credit unions are challenged with maintaining the competitive advantage that local, personalized, white-glove service has traditionally afforded them. This is why customer intelligence powered by data analytics helps midsize banks and credit unions thrive. However, they oftentimes struggle to achieve the valuable business insights that untapped data could provide to improve their operations.
It is unlikely that midsize and community banks will “out tech” large banks and fin-techs on their own. However, with the right partners, they have an opportunity to thrive by redefining the local experience and digitally transforming how they operate. Using the right data analytics, they can leverage their local knowledge with personalized customer intelligence to regain competitive advantage.
Customer Intelligence within Reach
Aunalytics’ Daybreak™ for Financial Services offers the ability to target, discover and offer the right services to the right people, at the right time. Built from the ground up for midsize community banks and credit unions, Daybreak for Financial Services is a cloud-native data platform with advanced analytics that empowers users to focus on critical business outcomes. The solution cleanses data for accuracy, ensures data governance across the organization, and employs AI and machine learning (ML) driven analytics to glean customer intelligence and insights from volumes of transactional data created in the business and updated daily. With daily insights powered by the Aunalytics cloud-native data platform, industry intelligence, and smart features that enable a variety of analytics solutions for fast, easy access to credible data, users can find the answers to such questions as:
- Which current customers that have a loan but not a deposit account?
- Who has a mortgage or wealth account with one of my competitors?
- Which customers with a credit score above 700 are most likely to open a HELOC?
- Which loans were modified from the previous day?
- Who are current members with a HELOC that are utilizing less than 25% of their line of credit?
Harnessing their data with Daybreak enables community banks and credit unions to discover patterns, insights, trends, and usage strategies helps to strengthen their position in regional markets and compete with large national banks. With Aunalytics’ customer intelligence data model, they are enabled to deliver timely personalized messages to customers, make data-driven product recommendations, measure campaign ROI, and grow net dollar retention.
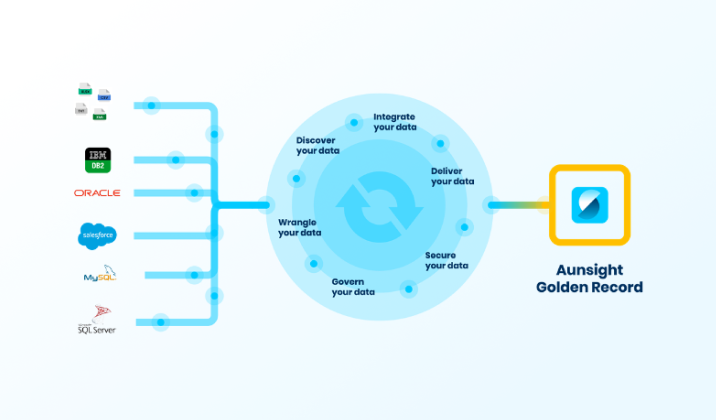
Aunsight Golden Record creates a single source of truth for credit union data
Credit unions have a great deal of data spread across various systems. However, it is impossible to create a centralized, accurate and up-to-date record of all of this data manually. Aunsight™ Golden Record automates this process by aggregating, cleansing, and merging data into a single source of truth so credit unions have access to an accurate record of their data in one place.
Watch the video below to learn more about how Aunsight Golden Record, along with the expertise of the Aunalytics team, can help credit unions quickly and painlessly take charge of their data:
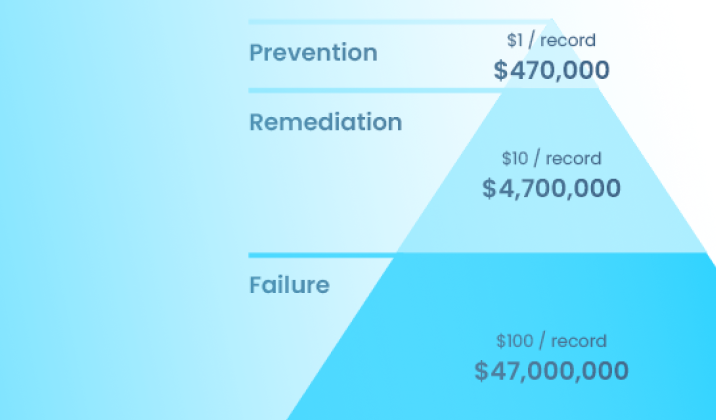
What is the 1-10-100 rule of data quality?
The 1-10-100 Rule pertains to the cost of bad quality. As digital transformation is becoming more and more prevalent and necessary for businesses, data across a company is integral to operations, executive decision-making, strategy, execution, and providing outstanding customer service. Yet, many enterprises are plagued by having data that is completely riddled with errors, duplicate records containing different information for the same human customer, different spellings for names, different addresses, more than one account for the same vendor (where pricing is not consistent), inconsistent information about a customer’s lifetime value or purchasing history, and reports and dashboards are often not trusted because the data underlying the display is not trusted. By its very nature, business operations often include manual data entry and errors are inherent.
The true cost to an organization of trying to conduct operations and make decisions based upon data riddled with errors is tough to calculate. That’s why G. Loabovitz and Y. Chang set out to conduct a study of enterprises to measure the cost of bad data quality. The 1-10-100 Rule was born from this research.
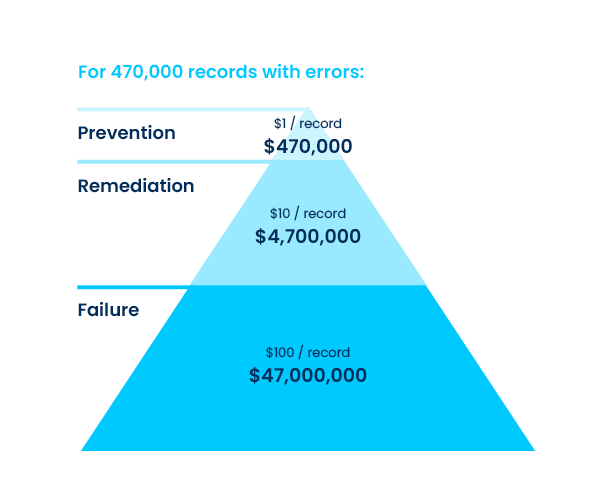 In data quality, the cost of verifying a record as it is entered is $1 per record. The cost of remediation to fix errors after they are created is $10 per record. The cost of inaction is $100 per record per year.
In data quality, the cost of verifying a record as it is entered is $1 per record. The cost of remediation to fix errors after they are created is $10 per record. The cost of inaction is $100 per record per year.
The Harvard Business Review reveals that on average, 47% of newly created records contain errors significant enough to impact operations.
If we combine the 1-10-100 Rule, using $100 per record for failing to fix data errors, with the Harvard Business Review statistic on the volume of such errors typical for an organization, the cost of poor data quality adds up rapidly. For an enterprise having 1,000,000 records, 470,000 have errors each costing the enterprise $100 per year in opportunity cost, operational cost, etc. This costs the enterprise $47,000,000 per year. Had the enterprise cleansed the data, the data clean-up effort would have cost $4,700,000 and had the records been verified upon entry, the cost would have been $470,000. Inherit in business services are errors caused by human manual data entry. Even with humans eyeballing records as they are entered, errors escape. This is why investing in an automated data management platform with built-in data quality provides a huge cost savings to an organization. Our solution, Aunsight Golden Record, can help organizations mitigate these data issues by automating data integration and cleansing.
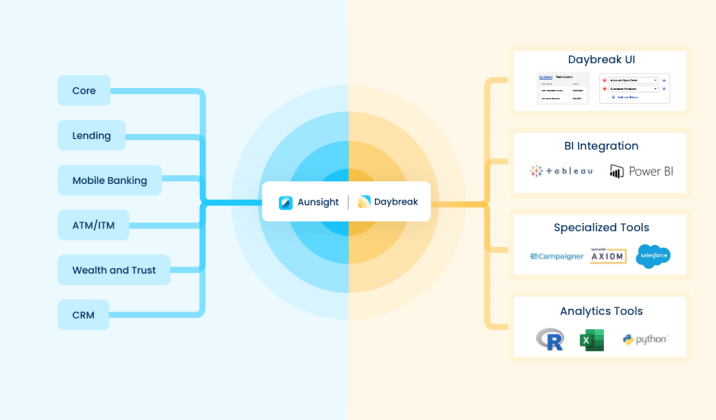
Daybreak's built-in data connectors and integrations speed insights for financial institutions
Got data? There’s a Daybreak connector for that! Our customer intelligence data platform, Daybreak™ for Financial Services, has built-in connectors for the financial services industry so credit unions and banks can put an end to siloed, disparate data. Daybreak connects to most relevant data sources, including core, lending, wealth, CRMs, and mobile banking. Whether structured or unstructured, on-prem or in the cloud, Daybreak can handle all types of data and sources.
In addition, Daybreak can feed cleaned, updated data to other systems you may be using, including BI platforms or analytics tools, through pre-built integrations. Watch the video below to learn more about Daybreak’s connectors and integrations.

Failure to follow Data Privacy Compliance requirements can be costly. How can you prepare your business?
GDPR, CCPA and the newly coming CPRA (which goes into effect 1/1/2023) require intense data management, or the cost of non-compliance can rise to $1000 per record. These data privacy laws pertain broadly to personal information of consumers including:
- Account and login information
- GPS and other location data
- Social security numbers
- Health information
- Drivers license and passport information
- Genetic and biometric data
- Mail, email, and text message content
- Personal communications
- Financial account information
- Browsing history, search history, or online behavior
- Information about race, ethnicity, religion, union membership, sex life, or sexual orientation
CPRA requires businesses to inform consumers how long they will retain data (for each category of data) and the criteria used to determine that time period of what is “reasonably necessary.” Basically, you have to be prepared to justify the data collection, processing, and retention and tie it directly to a legitimate business purpose.
Now prohibited is “sharing” data (beyond buying and selling it), which is defined as: sharing, renting, releasing, disclosing, disseminating, making available, transferring or otherwise communicating orally, in writing, or by electronic of other means, a consumer’s personal information by the business to a third party for cross-context behavioral advertising, whether or not for monetary or other valuable consideration, including transactions between a business and a third party for the benefit of a business in which no money is exchanged. Arguably, this covers a business working with a marketing firm and sharing data with the agency about leads or prospects to employ cross-content behavioral advertising in a campaign.
Companies now need to be able to inform the consumer what type of data they have about customers, what business purposes it is used for, and retention periods. This information allows them to meet the expanded consumer rights given by the CPRA, including deleting data, limiting types of use for certain types of data, correcting data errors across the organization in every location where it lives, automating and executing data retention policies, and to be ready for auditing. While it is an ethical ruleset that has now been put in place, with Data Privacy Compliance active, companies now have to consider possible non-compliance costs in addition to operational and opportunity costs as well.
As a result of these requirements, companies are now in need of a data management system with built-in data governance to stay in compliance. These data management platforms must be capable of identifying, on a data field-by-data-field basis, where the data originates, each and every change made to the data, and each downstream user of the data (databases, apps, analytics, queries, extracts, dashboards). Without automated data management and governance, it will be humanly impossible to manually find this information by the deadlines required. You need to be able to automatically replicate changes made to the data to all locations where the data resides throughout your organization to make consumer directed corrections and deletions within the time limits prescribed.
Critical Success Factors for Data Accuracy Platforms
The data accuracy market is currently undergoing a paradigm shift from complex, monolithic, on-premise solutions to nimble, lightweight, cloud-first solutions. As the production of data accelerates, the costs associated with maintaining bad data will grow exponentially and companies will no longer have the luxury of putting data quality concerns on the shelf to be dealt with “tomorrow.”
When analyzing major critical success factors for data accuracy platforms in this rapidly evolving market, four are critically important to evaluate in every buyer’s journey. Simply put, these are: Installation, Business Adoption, Return on Investment and BI and Analytics.
Installation
When executing against corporate data strategies, it is imperative to show measured progress quickly. Complex installations that require cross-functional technical teams and invasive changes to your infrastructure will prevent data governance leaders from demonstrating tangible results within a reasonable time frame. That is why it is critical that next-gen data accuracy platforms be easy to install.
Business Adoption & Use
Many of the data accuracy solutions available on the market today are packed with so many complicated configuration options and features that they require extensive technical training in order to be used properly. When the barrier to adoption and use is so high, showing results fast is nearly impossible. That is why it is critical that data accuracy solutions be easy to adopt and use.
Return on Investment
The ability to demonstrate ROI quickly is a critical enabler for securing executive buy-in and garnering organizational support for an enterprise data governance program. In addition to being easy to install, adopt, and use, next-gen data accuracy solutions must also make it easy to track progress against your enterprise data governance goals.
Business Intelligence & Analytics
At the end of the day, a data accuracy program will be judged on the extent to which it can enable powerful analytics capabilities across the organization. Having clean data is one thing. Leveraging that data to gain competitive advantage through actionable insights is another. Data accuracy platforms must be capable of preparing data for processing by best-in-class machine learning and data analytics engines.
Look for solutions that offer data profiling, data enrichment and master data management tools and that can aggregate and cleanse data across highly disparate data sources and organize it for consumption by analytics engines both inside and outside the data warehouse.

Daybreak's Predictive Smart Features Add Additional Value for Credit Unions
Is your credit union in a position to hire experienced data scientists who will develop predictive algorithms to enrich your member relationships? With Aunalytics, you can take advantage an entire team of data science talent. Our customer intelligence data platform, Daybreak™ for Financial Services, includes industry relevant Smart Features™ —high value data fields created by our Innovation Lab using advanced AI to provide high-impact insights.
Watch the video below to learn more about how Smart Features provide additional value for credit unions.

How Cybersecurity Mitigation Efforts Affect Insurance Premiums, and How to Keep Your Business Secure
 Cyberattacks have increased sharply over the past year. According to an August 2021 survey by IDC, more than one-third of organizations globally have experienced a ransomware attack or breach that blocked access to systems or data over the last twelve months. As a result, insurance companies are tightening eligibility requirements for cybersecurity coverage and requiring their insured to maintain higher standards of data security in order to qualify for better rates, and sometimes for renewal at all. Rates are increasing—up to 100%—for 2022, even for companies without any cyber incidents.
Cyberattacks have increased sharply over the past year. According to an August 2021 survey by IDC, more than one-third of organizations globally have experienced a ransomware attack or breach that blocked access to systems or data over the last twelve months. As a result, insurance companies are tightening eligibility requirements for cybersecurity coverage and requiring their insured to maintain higher standards of data security in order to qualify for better rates, and sometimes for renewal at all. Rates are increasing—up to 100%—for 2022, even for companies without any cyber incidents.
If you have received a renewal notice with a shocking sticker price for 2022, it is time to review your internal controls and security to learn if you can put in place further data protection to lower your rate. Worse, if you have received a notice that your business insurance policies are now excluding cyber coverage, data theft, or privacy breaches, you may be forced to shop for new cyber coverage at a time when attacks are at an all-time high. Without adequate security controls, obtaining coverage may be impossible. Due to the high cost of data breach incidents, you need to make sure that you are eligible for cyber coverage, but what does it take for 2022?
Aunalytics compliance and security experts are ready to help. We provide Advanced Security and Advanced Compliance managed services including auditing your practices, and helping you to mature your business cybersecurity processes, technology and safeguards to meet the latest standards and prevent new cyberattack threats as they emerge. Security maturity is a journey, and best practices have changed dramatically over the years. Threats evolve over time and so too must your cyber protection for your business to remain compliant and operational.

Think your financial institution is immune to ransomware? Think again.
Many organizations in the financial services sector don’t expect to be hit by ransomware. In the recent State of Ransomware in Financial Services 2021 survey by Sophos, 119 financial services respondents indicated that their organizations were not hit by any ransomware attacks in the past year, and they do not expect to be hit by them in the future either.
The respondents mentioned that their confidence relied on the following beliefs:
- They are not targets for ransomware
- They possess cybersecurity insurance against ransomware
- They have air-gapped backups to restore any lost data
- They work with specialist cybersecurity companies which run full Security Operations Centers (SOC)
- They have anti-ransomware technology in place
- They have trained IT security staff who can hinder ransomware attacks
It’s not all good news. Some results are cause for concern. Many financial services respondents that don’t expect to be hit (61%) are putting their faith in approaches that don’t offer any protection from ransomware.
- 41% cited cybersecurity insurance against ransomware. Insurance helps cover the cost of dealing with an attack, but doesn’t stop the attack itself.
- 42% cited air-gapped backups. While backups are valuable tools for restoring data post attack, they don’t stop you getting hit.
While many organizations believe they have the correct safeguards in place to mitigate ransomware attacks, 11% believe that they are not a target of ransomware at all. Sadly, this is not true. No organization is safe. So, what are financial institutions to do?
While advanced and automated technologies are essential elements of an effective anti-ransomware defense, stopping hands-on attackers also requires human monitoring and intervention by skilled professionals. Whether in-house staff or outsourced pros, human experts are uniquely able to identify some of the tell-tale signs that ransomware attackers have you in their sights. It is strongly recommended that all organizations build up their human expertise in the face of the ongoing ransomware threat.
